



自然言語処理 (NLP) の分野において、2018年にGoogleが発表したBERT (Bidirectional Encoder Representations from Transformers) は、革新的な深層学習モデルとして大きな注目を集めました。BERTは、大量のテキストデータを事前学習することで、文脈を理解し、様々なNLPタスクで高い精度を達成しました。本記事では、BERTの仕組みや応用例、利点と制限、さらには発展形について詳しく解説します。
BERTとは
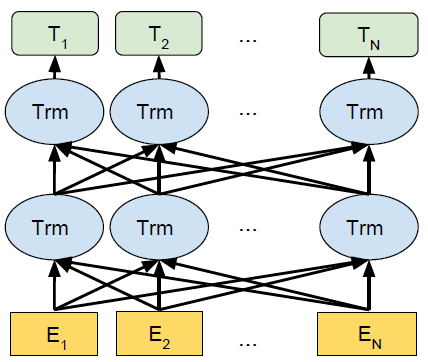
BERTは、Transformerアーキテクチャを採用した深層学習モデルです。Transformerは、系列データを処理するために、注意機構 (Attention Mechanism) を用いています。BERTは、Transformerのエンコーダー部分のみを使用し、入力テキストの双方向の文脈を捉えることができます。
BERTの特徴は、事前学習 (Pre-training) にあります。大量の未ラベル付きテキストデータを用いて、言語モデルを学習します。この事前学習によって、BERTは言語の一般的な特徴を捉えることができ、その後、少量のラベル付きデータを用いてファインチューニング (Fine-tuning) を行うことで、特定のタスクに適応させることができます。
BERTの事前学習
BERTの事前学習では、主に2つのタスクが用いられます。
NLP Pretraining – from BERT to XLNet – Title (bangliu.github.io)

- Masked Language Modeling (MLM): 入力テキストの一部をマスク (マスクトークン [MASK] に置換) し、マスクされた単語を予測するタスクです。これにより、BERTは文脈から単語を予測する能力を獲得します。
- Next Sentence Prediction (NSP): 2つの文が連続する文であるかどうかを予測するタスクです。これにより、BERTは文間の関係性を理解する能力を獲得します。
事前学習の損失関数は、MLMとNSPの損失の和として定義されます。
BERTのファインチューニング
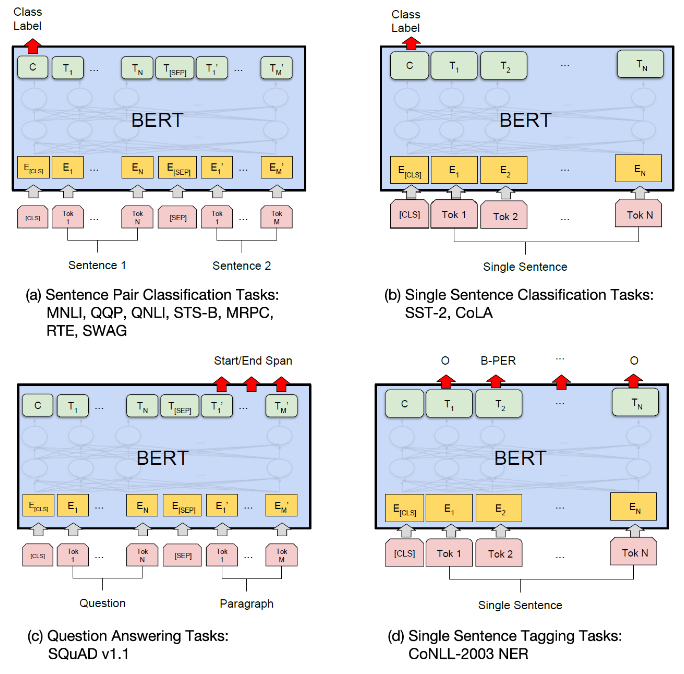
事前学習済みのBERTモデルを、特定のタスク (文章分類、質問応答、固有表現認識など) に適応させるために、ファインチューニングを行います。ファインチューニングでは、タスクに合わせて出力層を追加し、少量のラベル付きデータを用いてモデルを再学習します。
ファインチューニングの手順は以下の通りです。
- 事前学習済みのBERTモデルを読み込む
- タスクに応じた出力層を追加する
- ラベル付きデータを用いてモデルを再学習する
- 評価データでモデルの性能を評価する
ファインチューニングにより、少量のデータでも高い精度を達成することができます。
BERTの応用例
BERTは、様々なNLPタスクに応用されています。
- 文章分類: BERTを用いて、文章のカテゴリを予測することができます。例えば、ニュース記事の分類やセンチメント分析などがあります。
- 質問応答: BERTを用いて、質問に対する答えを文章から抽出することができます。例えば、SQuADデータセットを用いた質問応答タスクなどがあります。
- 要約: BERTを用いて、文章の要約を生成することができます。例えば、ニュース記事の要約や論文の要約などがあります。
- 固有表現認識: BERTを用いて、文章中の固有表現 (人名、地名、組織名など) を認識することができます。
- 機械翻訳: BERTを用いて、言語間の翻訳を行うことができます。例えば、英語から日本語への翻訳などがあります。
BERTの利点と制限
BERTの利点は、高い精度を達成できることです。事前学習によって言語の一般的な特徴を捉えているため、少量のデータでも高い性能を発揮します。また、様々なタスクに適応できる汎用性も魅力の一つです。
一方で、BERTの制限としては、計算コストが高いことが挙げられます。事前学習には大量のデータと計算資源が必要であり、ファインチューニングにも一定の計算コストがかかります。また、モデルのサイズが大きいため、推論時の速度やメモリ消費量も課題となります。
Pythonでの実装例
BERTを用いたPythonでの実装例を紹介します。ここでは、文章分類タスクを例に、PyTorchとHuggingFaceのtransformersライブラリを用いて、BERTのファインチューニングを行います。
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# トークナイザとモデルの読み込み
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 入力文章の準備
sentences = [
"I love this movie!",
"This film is terrible."
]
labels = [1, 0] # 1: 肯定的, 0: 否定的
# 入力文章のエンコーディング
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# ファインチューニング
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(3):
optimizer.zero_grad()
outputs = model(**inputs, labels=torch.tensor(labels))
loss = outputs.loss
loss.backward()
optimizer.step()
# 推論
model.eval()
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1)
print(predictions) # tensor([1, 0])この例では、BERTを用いて文章の感情分析 (肯定的か否定的か) を行っています。事前学習済みのBERTモデルを読み込み、少量のラベル付きデータを用いてファインチューニングを行った後、新しい文章に対して推論を行っています。
まとめ
BERTは、自然言語処理の分野に大きな影響を与え、多くの研究者や企業がBERTをベースにした新しいモデルを開発しています。今後は、より大規模なデータを用いた事前学習や、タスク特化型のアーキテクチャの開発など、さらなる進化が期待されます。
また、BERTを用いた実用的なアプリケーションの開発も進んでいくでしょう。対話システム、文書検索、自動要約など、様々な分野でBERTが活用されることが予想されます。
BERTは、自然言語処理の発展に大きく貢献し、今後もその重要性は増していくと考えられます。BERTを理解し、活用することは、自然言語処理に携わる研究者や開発者にとって不可欠な知識となるでしょう


コメント