




Pythonのデータ可視化ライブラリSeabornは、データ分析の効率とわかりやすさを格段に高めてくれます。その中でもcatplotは、カテゴリデータの視覚化に特化した非常に便利な機能です。本記事では、catplotの基本的な使い方から応用まで、実例を交えながら解説していきます。
Catplotとは?
Catplotは、カテゴリ型の変数を含むデータセットの関係を可視化するためのSeabornの機能です。カテゴリ型の変数とは、離散的な値を持つ変数のことであり、性別や地域などが代表的な例です。Catplotは、カテゴリごとにデータを分析し、パターンや相関関係を可視化するのに役立ちます。
Catplotの種類
カテゴリプロットでは、主に3つの種類があります。そこから表現方法の違いで細分化すると8種類となります。
- Categorical scatterplots:散布図
- stripplot() (with kind=”strip”; the default)
- swarmplot() (with kind=”swarm”)
- Categorical distribution plots:分布図
- boxplot() (with kind=”box”)
- boxenplot() (with kind=”boxen”)
- violinplot() (with kind=”violin”)
- Categorical estimate plots:推定プロット
- barplot() (with kind=”bar”)
- countplot() (with kind=”count”)
- pointplot() (with kind=”point”)
データの準備
今回は、seabornでサンプルとして準備されているデータを呼び出して使用します。
import seaborn as sns
import matplotlib.pyplot as plt
tips = sns.load_dataset("tips")すべてに共通の引数
- data: プロットするデータのデータフレーム
- x: x軸のカテゴリデータの列名
- y: y軸のデータの列名
- row/col: 行列方向にプロットを小分けする変数の列名
Categorical scatterplots:散布図
stripplot()の実装
Strip Plotは、カテゴリごとのデータの分布や個々のデータ点を視覚的に表現するのに役立ちます。
- 個々のデータ点の表示: 各データポイントがそのままプロットされ、その分布が視覚的にわかりやすくなります。これにより、データの分散や外れ値などを素早く把握することができます。
- カテゴリごとの比較: 異なるカテゴリに属するデータの分布を比較するのに適しています。カテゴリごとにデータポイントの密度や分布を比較することができます。
- Jittering(ジッタリング): データポイントが重なる場合、ランダムなノイズを追加して、データの重なりを解消することができます。これにより、データの分布がより明確に表示されます。
最小コード
sns.catplot(x="day", y="total_bill", data=tips);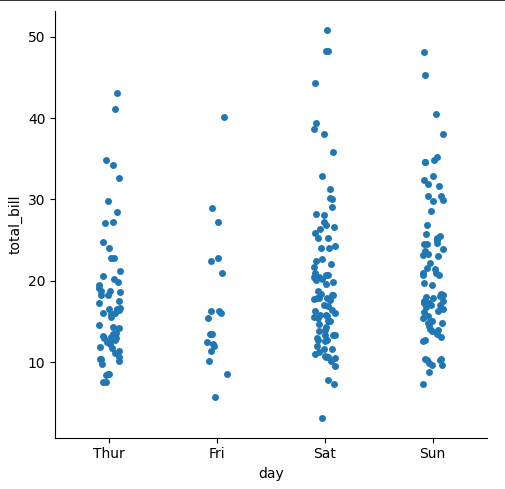
様々なオプション
jitter
一つの軸に対してプロットする際の横(縦)方向のずれの値を設定できる箇所だが、Falseを置くことでずれをなくすことも可能
sns.catplot(data=tips, x="day", y="total_bill", jitter=False)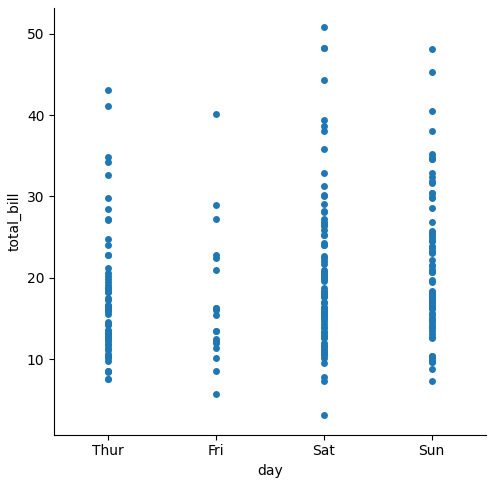
hue
ここに設定した列名のカテゴリに応じて色分けを行うことができる。
sns.catplot(data=tips, x="day", y="total_bill", hue="sex")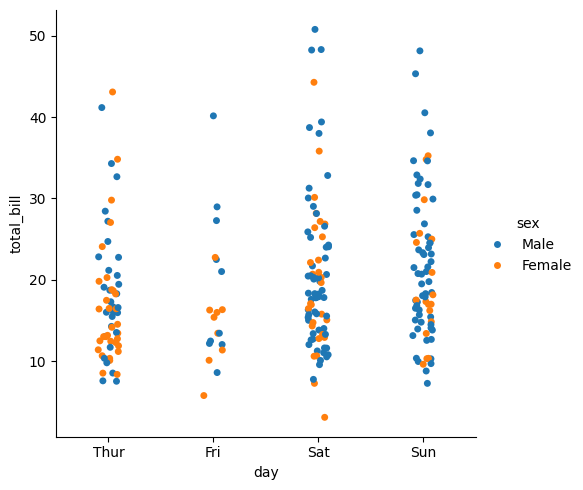
dodge
上記のhueで色分けを行った場合に、そのカテゴリごとに軸を避けて描画できます。
sns.catplot(data=tips, x="day", y="total_bill", hue='sex', dodge=True)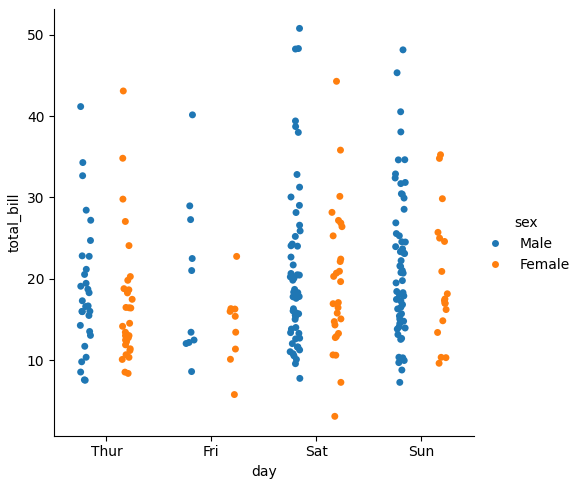
これ以外にも今縦に積み上げているものをそのまま90度倒して横方向にするオプションに加え、プロットの色を指定したりサイズを指定することが可能です。
swarmplot()の実装
Strip Plotと同様に、個々のデータポイントをプロットしますが、Swarm Plotではデータポイント同士が重ならないように配置されます。しばしば「ミツバチの群れ」と称されるような見た目にかわります。
- 個々のデータ点の表示: 各データポイントがそのままプロットされ、その分布が視覚的にわかりやすくなります。これにより、データの分散や外れ値などを素早く把握することができます。
- データポイントの重なり防止: データポイント同士が重ならないように配置されます。これにより、データポイントの密度や分布をより正確に理解することができます。
- カテゴリごとの比較: 異なるカテゴリに属するデータの分布を比較するのに適しています。カテゴリごとにデータポイントの密度や分布を比較することができます。
あまりに多いデータセットには向いていないようです。公式がアナウンスしています。
sns.catplot(data=tips, x="day", y="total_bill", hue="sex", kind="swarm")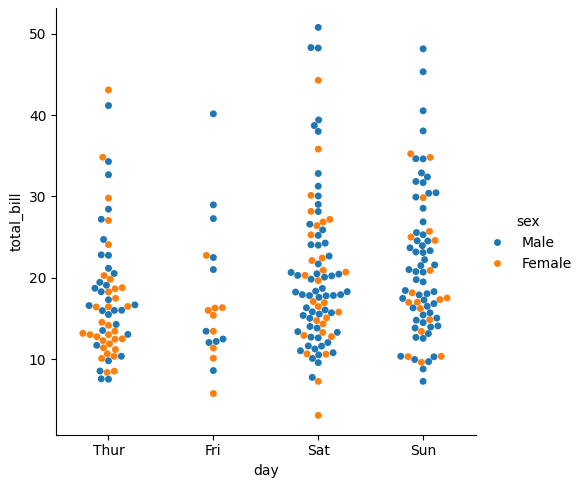
様々なオプションについては、stripplotと同じのものが非常に多いので割愛します。
Categorical distribution plots:分布図
boxplot()の実装
データセットの中央値、四分位数、外れ値などの統計的特性を可視化するのに役立ちます。以下に、Box Plotの主な特徴と使用方法を説明します。
- 中央値と四分位範囲の表示: 箱の中央にはデータの中央値が表示され、箱の上下の端には第1四分位数(25パーセンタイル)と第3四分位数(75パーセンタイル)が表示されます。
- 箱の高さ: 箱の高さは、データの第1四分位数から第3四分位数までの範囲であり、データの中央50%を表します。箱の高さが短いほどデータのばらつきが小さいことを意味します。
- ひげの表示: 箱の上下に延びる線(ひげ)は、データの範囲を表します。通常、ひげの長さは第1四分位数から1.5倍の四分位範囲と第3四分位数から1.5倍の四分位範囲の外にあるデータポイントまで伸びます。外れ値はひげの外側に単独で表示されます。
- 外れ値の表示: 箱ひげ図は、データの中にある外れ値を視覚的に特定するのに役立ちます。外れ値は通常、ひげの外側に単独でプロットされます。
最小コード
sns.catplot(x="day", y="total_bill", kind="box", data=tips)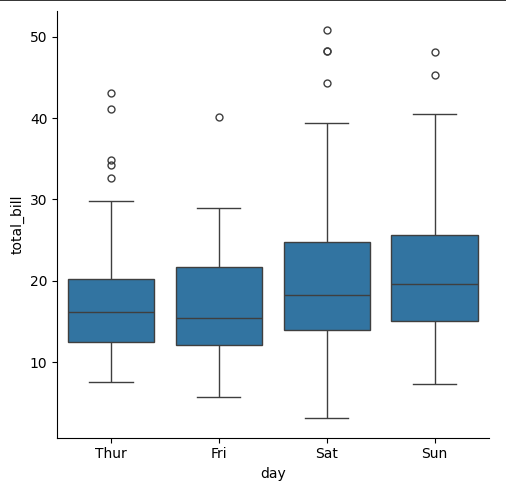
様々なオプション
様々なオプションについては、stripplotと同じのものが非常に多いので特に挙動が変わるもの独自のものにのみフォーカスすることにします。
hue
ここに設定した列名のカテゴリに応じてそれぞれを箱ひげ図にして色分け描画できる。
sns.catplot(data=tips, x="day", y="total_bill", hue="smoker", kind="box")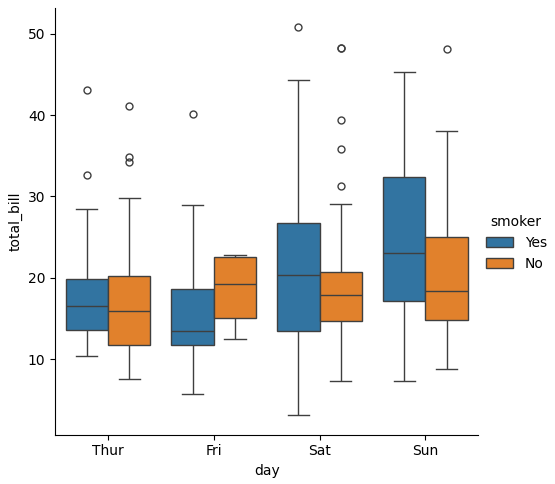
fill
塗りつぶしを行うかどうかを設定できます。
sns.catplot(data=tips, x="day", y="total_bill", hue="smoker", kind="box", fill=False)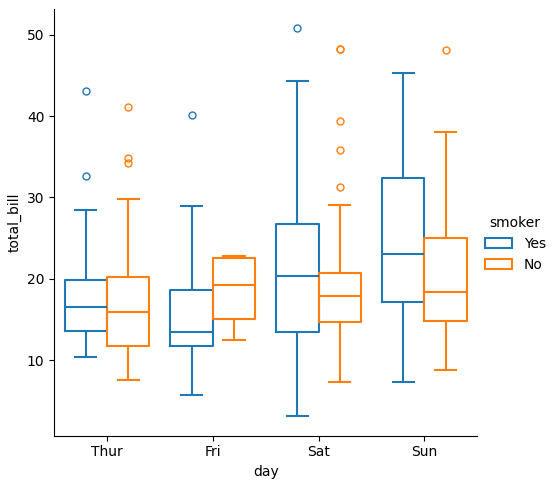
boxenplot()の実装
Boxen Plotは、データの分布や中央値、四分位数などの統計的特性を視覚的に表現するのに役立ちます。以下のような特徴があります。
- 拡張された箱ひげ図: 通常の箱ひげ図よりも多くの情報を提供します。特に、中央値や四分位数だけでなく、さらに深い統計情報を表示します。
- サブグループの可視化: データをサブグループに分割して比較する場合に便利です。これにより、異なるカテゴリや条件におけるデータの分布を比較することができます。
- データの密度の表示: データの分布に関する情報をより詳細に知ることができます。特に、データの密度が高い領域や外れ値が存在する領域を明確に表示します。
最小コード
sns.catplot(x="day", y="total_bill", kind="boxen", data=tips)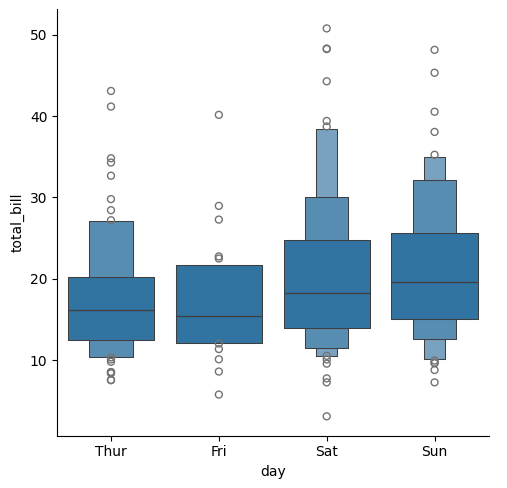
様々なオプション
様々なオプションについては、stripplotと同じのものが非常に多いので特に挙動が変わるもの独自のものにのみフォーカスすることにします。
saturation
グラフを描画する際に彩度を下げた方が見栄えがよくなることがよくあります、そういったとき、塗りつぶしの色を描画する元の彩度の比率で指定することができます。
sns.catplot(x="day", y="total_bill", kind="boxen", data=tips, saturation=.2)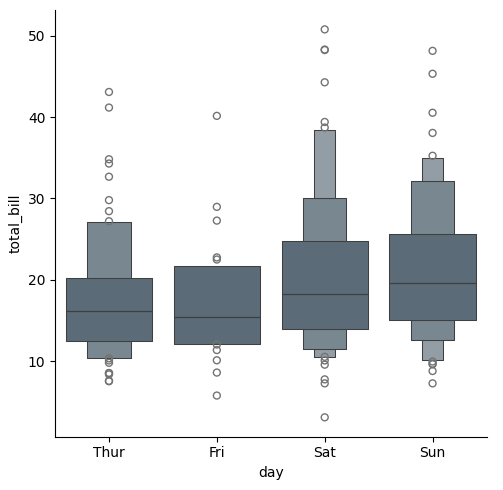
violinplot() の実装
バイオリンプロットは、データの分布形状や中央値、四分位範囲などの統計的特性を視覚的に表現するのに役立ちます。以下に、Violin Plotの主な特徴と使用方法を説明します。
- カーネル密度推定: バイオリンプロットは、各データセットのカーネル密度推定を行い、データの分布をなめらかな曲線で表現します。これにより、データの分布形状が視覚的に把握できます。
- 中央値と四分位範囲の表示: バイオリンプロットには、中央値や四分位範囲などの要約統計量が含まれており、各データセットの中央値と四分位範囲を示します。
- データの密度: バイオリンプロットの幅は、各データセットの密度を表します。幅が広いほどデータが集中していることを示し、幅が狭いほどデータが分散していることを示します。
- 分布の比較: 複数のデータセットを同時にプロットすることで、異なるグループ間のデータ分布を比較することができます。
最小コード
sns.catplot(data=tips, x="total_bill", y="day", hue="sex", kind="violin")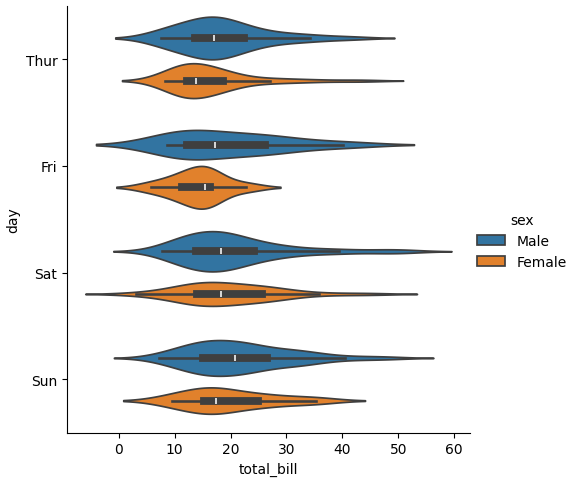
様々なオプション
様々なオプションについては、stripplotと同じのものが非常に多いので特に挙動が変わるもの独自のものにのみフォーカスすることにします。
split
バイオリンを上下に「分割」することも可能で、先ほどの二つのバイオリンプロットの上側を男性、下側を女性にすることでスペースをより効率的に使用できます。
sns.catplot(data=tips, x="total_bill", y="day", hue="sex", kind="violin", split=True)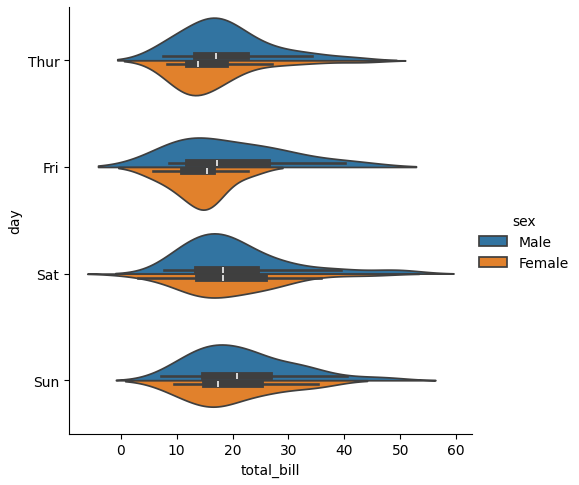
inner
ヴァイオリン内部のデータ表現を変更できます。デフォルトは「box」で箱ひげ図が描画される、「point」「stick」で各測定値にポイントやラインを描画が可能であり、「quart」で四分位数を表示できます。
sns.catplot(data=tips, x="total_bill", y="day", hue="sex", kind="violin", split=True, inner='stick')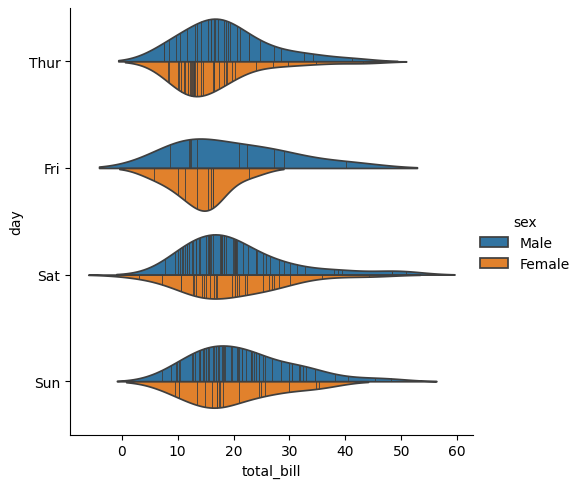
Categorical estimate plots:推定プロット
barplot() の実装
Bar Plot(棒グラフ)は、カテゴリ別のデータを比較するために使用されるグラフィカルな手法です。カテゴリ別の数値データを棒状の縦棒で表現し、それらの高さを用いて相対的な値を比較します。以下に、Bar Plotの主な特徴と使用方法を説明します。
- カテゴリ別の比較: Bar Plotは、異なるカテゴリのデータを簡単に比較できるようにします。例えば、商品カテゴリごとの売上や各月の売上など、カテゴリごとのデータを比較するのに適しています。
- 相対的な大きさの視覚化: 棒の高さは、対応するカテゴリのデータの値を表します。高さが高いほど、そのカテゴリの値が大きいことを示します。
- 複数の変数の比較: 複数のカテゴリや条件を含むデータセットの場合、複数の棒グラフを並べて表示することで、異なる条件やカテゴリ間の比較が容易になります。
最小コード
sns.catplot(data=tips, x="day", y="total_bill", kind="bar")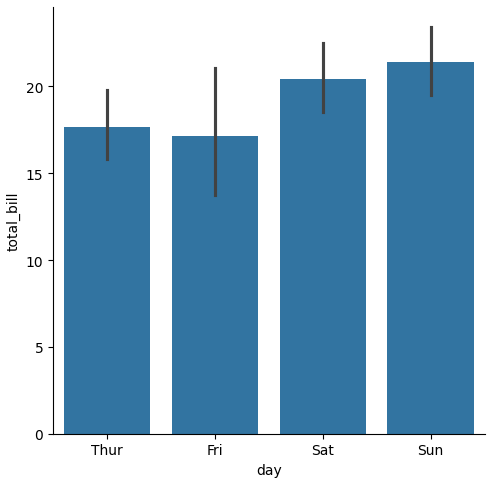
countplot() の実装
Count Plotは、カテゴリごとのデータの出現回数を可視化するためのグラフです。各カテゴリに属するデータ点の数を棒グラフやヒストグラムの形式で表示し、カテゴリごとの頻度を比較します。主にカテゴリ型の変数の分布を理解するために使用されます。
- カテゴリの頻度の比較: Count Plotは、異なるカテゴリのデータの出現回数を直感的に比較できるようにします。カテゴリごとの頻度の違いを視覚的に把握できます。
- データの集計と可視化: データセット内のカテゴリデータの出現回数を集計し、それを棒グラフやヒストグラムの形式で視覚化します。
- カテゴリ型変数の分析: 主にカテゴリ型の変数(例:性別、地域、カテゴリなど)の分布を分析するのに適しています。
最小コード
sns.catplot(data=tips, x="day", kind="count")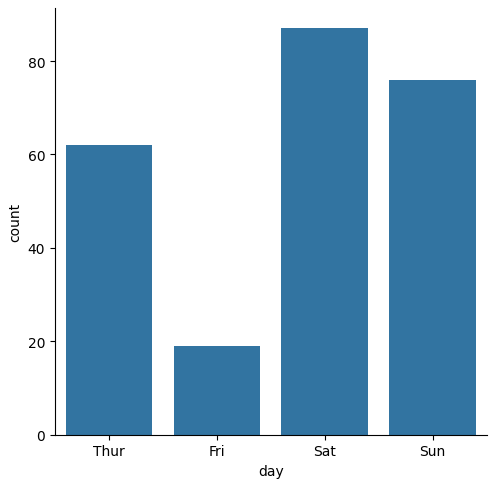
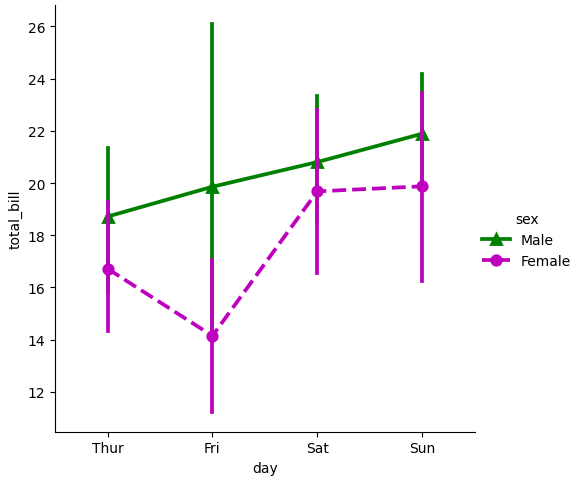
pointplot() の実装
Point Plotは、カテゴリ変数と数値変数の関係を可視化するためのグラフです。各カテゴリの平均値や中央値などの集計値をポイントとしてプロットし、その間の信頼区間を線で表現します。Point Plotは、異なるカテゴリ間の数値の比較や傾向の把握に役立ちます。
- カテゴリ間の数値比較: Point Plotは、カテゴリごとの数値の平均や中央値をポイントで示すことで、異なるカテゴリ間の数値の比較を容易にします。
- 信頼区間の表示: ポイントの周りに表示される線は、信頼区間を表します。これにより、集計値のばらつきや統計的な信頼性を視覚的に評価できます。
- 傾向の把握: カテゴリごとのポイントと信頼区間を比較することで、異なるカテゴリ間の傾向やパターンを把握するのに役立ちます。
最小コード
sns.catplot(data=tips, x="day", y="total_bill", kind="point", hue="sex")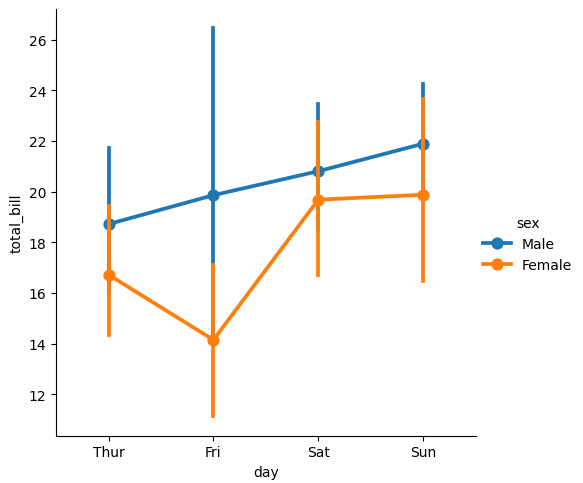
それぞれのスタイルを個別に変更する
- カラーマップの指定: paletteパラメータを使用して、辞書型で異なるカテゴリに対応する色を指定することができます。これにより、デフォルトの色以外の色を使用してプロットを作成できます。
- ラインスタイルの指定: linestylesパラメータを使用して、リスト型で異なるカテゴリに対応するラインのスタイルを指定することができます。
- マーカーの指定: markersパラメータを使用して、リスト型で異なるカテゴリに対応するマーカーを指定することができます。
sns.catplot(
data=tips, x="day", y="total_bill", kind="point", hue="sex",
palette={"Male": "g", "Female": "m"},
markers=["^", "o"], linestyles=["-", "--"]
)
まとめ
Seabornのcatplotを使用することで、様々な種類のカテゴリデータを効果的に可視化することができます。散布図、分布図、推定プロットなど、さまざまな視覚化手法を使いこなし、データの特徴やパターンを理解しましょう。

コメント