




今回は画像生成分野における革新的な取り組み「DiffusionGPT」について、詳しく解説していきたいと思います。
DiffusionGPTは、大規模言語モデル(LLM)を活用することで、優れた生成モデルをシームレスに統合し、多様なプロンプトを効率的に解析できる画期的なフレームワークです。従来の画像生成手法の課題を解決し、幅広い分野で卓越した性能を発揮します。
本記事では、DiffusionGPTの仕組みや特徴を丁寧に解説するとともに、実際のPythonコードを交えながら、その実装方法についても触れていきます。AI分野に関心のある方はもちろん、プログラミングに興味のある方にもおすすめの内容となっています。
それでは、早速DiffusionGPTの世界に飛び込んでみましょう!
DiffusionGPTとは
DiffusionGPTは、LLMを活用した革新的な画像生成フレームワークです。優れた生成モデルを統合し、多様なプロンプトを効率的に解析することで、高品質の画像生成を実現します。
従来の画像生成手法では、以下のような課題がありました。
- モデルの限界:汎用性の高いStable Diffusionモデルは特定の分野での性能が低く、特化型モデルは汎用性に欠ける
- プロンプトの制約:学習時のテキスト情報は記述文が中心で、指示文やインスピレーション文など多様なプロンプトへの対応が難しい
DiffusionGPTは、これらの課題を解決するために開発されました。LLMをコア制御として活用し、プロンプト解析からモデル選択、画像生成までのワークフローを一貫して管理します。
以下に、DiffusionGPTのワークフローを示します。
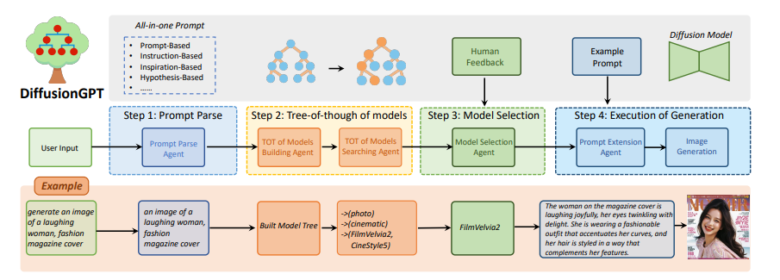
- プロンプト解析:入力されたプロンプトから、重要なテキスト情報を抽出
- モデルツリーの構築と検索:事前知識をもとにモデルツリーを構築し、入力プロンプトに合わせて最適なモデルを検索
- モデル選択:人間のフィードバックを取り入れながら、生成に最適なモデルを選択
- 画像生成の実行:選択されたモデルを用いて、高品質の画像を生成
このワークフローにより、DiffusionGPTは幅広いプロンプトや分野に対応でき、高い汎用性と卓越した性能を実現しています。
実際に試せるようにDemoを準備してくれてます。

全体像
プロンプト解析の仕組み
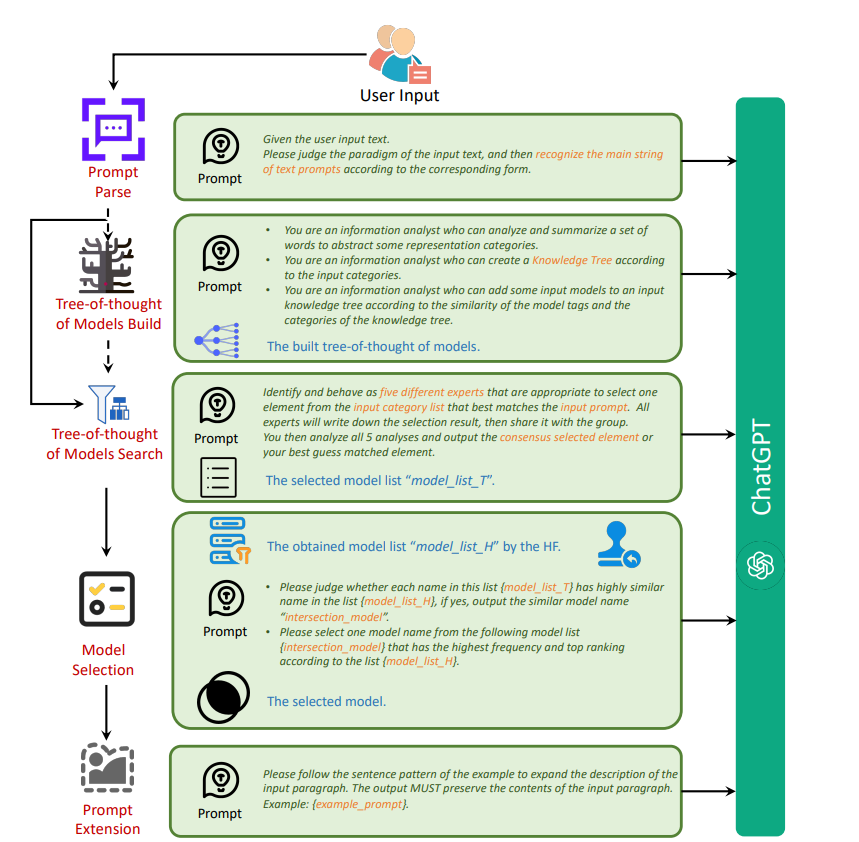
DiffusionGPTは、まず入力されたプロンプトを解析します。プロンプト解析エージェントがLLMを活用して、プロンプトから重要なテキスト情報を抽出するのです。
プロンプトには以下のような種類があります。
- プロンプトベース:入力全体をプロンプトとして使用
- 指示ベース:指示の中核部分をプロンプトとして抽出
- インスピレーションベース:願望対象をプロンプトとして抽出
- 仮説ベース:仮説条件と行動対象をプロンプトとして抽出
プロンプト解析エージェントは、これらの形式を識別し、ノイズの影響を軽減しながら、ユーザーが生成したい核となるコンテンツを正確に認識します。
モデルツリーによる効率的な検索
プロンプト解析の次のステップは、膨大なモデルライブラリから適切な生成モデルを選択することです。しかし、モデルの数が多いため、全てのモデルをLLMに同時に入力して選択するのは現実的ではありません。
そこでDiffusionGPTでは、Tree-of-Thought(TOT)の概念に基づくモデルツリーを利用します。モデルツリーの検索機能を活用することで、モデルの候補を絞り込み、選択の精度を高めるのです。
モデルツリーは、以下の手順で自動構築されます。
- 全モデルの属性タグをTOTモデル構築エージェントに入力
- エージェントが主題ドメインとスタイルドメインからカテゴリを抽出
- スタイルカテゴリを主題カテゴリのサブカテゴリとして組み込み、2層の階層ツリー構造を確立
- 全モデルを属性に基づいて適切なリーフノードに割り当て
このように自動構築されるため、新しいモデルを追加する際にも、エージェントが属性に基づいてモデルツリーの適切な位置に配置します。
モデルツリーの検索は、TOTモデル検索エージェントが幅優先探索を用いて行います。各レベルでカテゴリとプロンプトを比較し、最も一致度の高いカテゴリを選択。この繰り返しにより、最終的なモデル候補セットを導出します。
人間のフィードバックを取り入れたモデル選択
モデル選択の段階では、前段で得られたモデル候補セットから、画像生成に最も適したモデルを特定します。ここでは、オープンソースコミュニティから得られる限られた属性情報では、詳細なモデル情報をLLMに提供しながら最適なモデルを決定するのが難しいという課題があります。
DiffusionGPTは、この課題に対処するために、人間のフィードバックを活用するモデル選択エージェントを導入しています。アドバンテージデータベース技術を用いて、モデル選択プロセスを人間の好みに合わせるのです。
具体的には、以下のような手順でモデル選択を行います。
- 1万件のプロンプトに基づくモデル生成結果に対して報酬モデルでスコア計算し、情報をデータベースに保存
- 入力プロンプトと1万件のプロンプトの意味的類似度を計算し、上位5件のプロンプトを特定
- オフラインデータベースから各モデルの性能情報を取得し、選択されたプロンプトごとに上位5モデルを選択
- TOT段階で得られたモデル候補セットと、上記の5×5モデルセットの共通部分を特定
- 出現確率が高く、ランキングが上位のモデルを最終的に選択
プロンプト拡張による生成品質の向上
最適なモデルが選択されたら、得られた核となるプロンプトを用いて、目的の画像を生成します。この際、プロンプト拡張エージェントを用いてプロンプトを自動的に拡張することで、生成品質を向上させることができます。
DiffusionGPTの起動手順
プロンプト拡張エージェントは、選択されたモデルのプロンプト例を参照しながら、入力プロンプトをより詳細で表現力豊かなものへと拡張します。これにより、生成される画像の質が大幅に改善されるのです。
DiffusionGPTを実際に試してみたい方のために、ここではGitHubリポジトリからソースコードを取得し、環境を設定して起動するまでの手順を説明します。
前提条件
- Pythonがインストールされていること(バージョン3.6以上)
- GitHubアカウントを持っていること
手順
- リポジトリのクローン
まず、DiffusionGPTのGitHubリポジトリをローカル環境にクローンします。ターミナルまたはコマンドプロンプトで以下のコマンドを実行してください。
git clone https://github.com/DiffusionGPT/DiffusionGPT.git- 必要なライブラリのインストール
リポジトリのルートディレクトリに移動し、必要なPythonライブラリをインストールします。
cd DiffusionGPT pip install -r requirements.txt- 環境変数の設定
.envファイルを作成し、以下の内容を記述してください。OPENAI_API_KEY=your_openai_api_keyの部分を、自身で発行したOpenAI APIキーに置き換えてください。
- DiffusionGPTの起動
以下のコマンドを実行して、DiffusionGPTを起動します。
python main.py- プロンプトの入力
DiffusionGPTが起動したら、プロンプトを入力して画像生成を開始できます。例えば、以下のようなプロンプトを入力してみてください。
A beautiful sunset over a serene beach以上が、DiffusionGPTを起動するまでの手順です。手順に沿って進めていけば、簡単にDiffusionGPTを試すことができます。
DiffusionGPTの優位性

DiffusionGPTは、従来の画像生成手法と比較して、以下のような優位性を持っています。
- 多様な入力プロンプトに対応可能で、汎用性が高い
- 人間のフィードバックを取り入れ、ユーザーの好みに合わせた生成が可能
- TOTとアドバンテージデータベースにより、高精度なモデル選択が可能
- プロンプト拡張により、生成画像の品質が向上
- 学習不要のためプラグアンドプレイで導入可能で、拡張性が高い
これらの優位性により、DiffusionGPTは画像生成の分野に大きな進歩をもたらすことが期待されています。
今後の展望
DiffusionGPTは画像生成の分野に新しい可能性を開いていますが、まだいくつかの課題が残されています。
- LLMの最適化プロセスへのフィードバック組み込みによる、よりきめ細やかなプロンプト解析とモデル選択の実現
- モデル候補の拡充による、より多彩で印象的な生成結果の追求
- テキストから画像への変換以外のタスクへの応用(制御可能な生成、スタイル変換、属性編集など)
DiffusionGPTの発展により、AIによる画像生成はさらなる高みへと到達することでしょう。
まとめ
本記事では、LLMを活用した革新的な画像生成フレームワーク「DiffusionGPT」について詳しく解説しました。
DiffusionGPTは、優れた生成モデルをシームレスに統合し、多様なプロンプトを効率的に解析することで、高品質の画像生成を実現します。プロンプト解析、モデルツリーによる検索、人間のフィードバックを取り入れたモデル選択、プロンプト拡張など、そのワークフローを丁寧に説明しました。
また、Pythonでの実装例を交えながら、各ステップの具体的な仕組みにも触れました。DiffusionGPTは学習不要でプラグアンドプレイ可能なため、導入が容易で拡張性にも優れています。


コメント