




GANsって何?画像生成AIの基礎を理解する
最近、AIが描いた絵とか、AIが作った画像とか、よく見かけますよね。あれ、どうやって作られているか気になったことありませんか?
実は、その技術の根幹にあるのが「GAN(Generative Adversarial Networks)」、日本語では「敵対的生成ネットワーク」と呼ばれるものです。2014年にIan Goodfellowという研究者が発表した論文で提案されたんですが、これが本当に画期的で、その後の画像生成AI技術の発展に大きな影響を与えました。
今回は、このGANsについて、できるだけわかりやすく解説していこうと思います。数式とか難しい部分もあるんですが、基本的な仕組みはそんなに複雑じゃないので、ぜひ最後まで読んでみてください。
GANsの基本的な仕組み
GANsの考え方、実はすごくシンプルです。例えるなら、贋作を作る人と、それを見抜く鑑定士が競い合っているようなイメージです。
具体的には、2つのニューラルネットワークが登場します。1つ目が「Generator(生成器)」で、これはランダムなノイズから画像を生成する役割を持っています。もう1つが「Discriminator(識別器)」で、こっちは与えられた画像が本物なのか、それともGeneratorが作った偽物なのかを判定します。
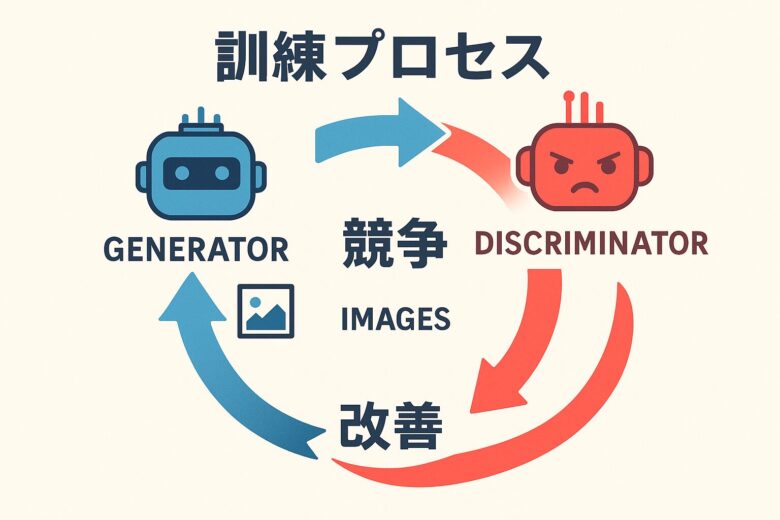
で、この2つが同時に訓練されるんです。Generatorは「Discriminatorを騙せるような、よりリアルな画像を作ろう」と頑張り、Discriminatorは「本物と偽物をちゃんと見分けられるようになろう」と頑張る。この競争を繰り返すことで、Generatorがどんどん上手になっていって、最終的には人間の目で見ても本物と区別がつかないような画像を生成できるようになるわけです。
論文では、これを「二人ゼロ和ゲーム」と表現していて、まさにゲーム理論的なアプローチなんですよね。一方が得をすれば、もう一方が損をする。この緊張関係が、お互いを成長させる原動力になっています。
もう少し詳しく:数学的な話
ここからちょっと数式が出てきます。苦手な人は飛ばしても大丈夫ですが、理解できるとGANsの本質が見えてくるので、ぜひ挑戦してみてください。
GANsで最適化しようとしているのは、こういう目的関数です:
$$\min_G \max_D V(D,G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1-D(G(z)))]$$
これ、一見複雑に見えますけど、やってることは実はシンプルです。左側の項は「本物の画像に対して、Discriminatorが高い確率を割り当てる」ことを促していて、右側の項は「生成された偽物の画像に対して、Discriminatorが低い確率を割り当てる」ことを促しています。
Discriminatorはこの全体の値を最大化しようとするし、Generatorは最小化しようとする。つまり、Generatorの立場からすると、右側の項を小さくしたい、言い換えれば「Discriminatorに高い確率を出させたい」わけです。
任意のGeneratorに対して、最適なDiscriminatorの形は理論的に以下のように表せます:
$$D_G^*(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)}$$
ここで\(p_{data}(x)\)は実際のデータ分布、\(p_g(x)\)はGeneratorが生成するデータ分布です。理想的には、訓練が完璧に進むと\(p_g = p_{data}\)となり、このときDiscriminatorは常に0.5を出力するようになります。つまり「コイン投げと同じで、もうどっちが本物かわからない」状態ですね。
実際の訓練の流れ
実装レベルでは、こんな感じで訓練が進みます:
- 訓練データから本物の画像のミニバッチをサンプリングして、同時にランダムノイズも生成します
- Discriminatorを更新します。本物の画像には「本物」というラベルを、Generatorが生成した画像には「偽物」というラベルを付けて学習させます
- 次にGeneratorを更新します。ここがちょっとトリッキーで、生成した画像に対して「本物」というラベルを付けてDiscriminatorに判定させ、その誤差を使ってGeneratorを学習させます
- このプロセスを延々と繰り返します
ただ、この訓練がけっこう難しくて、バランスを取るのが大変なんですよね。Discriminatorが強くなりすぎると、Generatorが学習できなくなるし、逆にGeneratorが強くなりすぎても、Discriminatorが無意味になってしまう。このバランス調整が、GANs研究の永遠のテーマみたいになってます。
論文での実験結果
Goodfellowらの論文では、MNIST、Toronto Face Database(TFD)、CIFAR-10といったデータセットで実験が行われています。
結果としては、従来の生成モデルと比べて、かなり鮮明で多様性のある画像が生成できることが示されました。特に面白いのが、潜在空間での補間実験です。ノイズ空間で線形補間を行うと、生成される画像も滑らかに変化していくんです。これって、モデルが単に訓練データを丸暗記してるんじゃなくて、ちゃんと意味のある特徴表現を学習できている証拠なんですよね。
実装について
Goodfellowらは、論文のコードをGitHubで公開しています。
ただ、正直に言うと、このコードは2014年当時のもので、TheanoとPylearn2という、今ではあまり使われていないフレームワークを使っています。なので、今から学ぶなら、PyTorchやTensorFlowで書き直されたバージョンを探した方がいいと思います。
もし今から実装するなら
今の時代にGANsを実装するなら、PyTorchかTensorFlowを使うのが一般的です。特にPyTorchは研究界隈で人気があって、柔軟性が高いので、いろいろ試しやすいですね。
基本的なコードの構造は、こんな感じになります:
for epoch in range(num_epochs):
# Discriminatorの訓練
real_images = get_real_batch()
noise = generate_random_noise()
fake_images = generator(noise)
d_loss_real = train_discriminator(real_images, label=1)
d_loss_fake = train_discriminator(fake_images, label=0)
# Generatorの訓練
noise = generate_random_noise()
fake_images = generator(noise)
g_loss = train_generator_via_discriminator(fake_images, label=1)
実際にはもっと複雑で、学習率の調整とか、正規化とか、いろいろテクニックがあるんですけど、基本的な流れはこういう感じです。
GANsの良いところ、難しいところ
論文では、GANsのメリットとデメリットがしっかり議論されています。
良いところ
まず、従来の生成モデルで必要だったマルコフ連鎖モンテカルロ法みたいな複雑な計算が要らないのが大きいです。バックプロパゲーションだけで訓練できるし、推論のための特殊なステップも不要。シンプルなのが美しいですよね。
あと、生成プロセスに幅広い関数を組み込めるのも魅力です。ネットワーク構造の自由度が高いので、いろんなバリエーションが作れます。
難しいところ
一番の問題は、訓練の不安定性です。これ、本当に厄介で、ハイパーパラメータをちょっといじっただけで、全然うまく学習しなくなったりします。GeneratorとDiscriminatorのバランスを保つのが難しくて、片方が強くなりすぎると、もう片方が学習できなくなる「モード崩壊」という現象が起きたりします。
あと、生成された分布\(p_g(x)\)を明示的に表現できないので、モデルの評価が難しいという問題もあります。「ちゃんと学習できてるのか?」を定量的に測るのが、意外と大変なんですよね。
GANsのその後
2014年の登場以来、GANsは爆発的に研究が進んで、いろんなバリエーションが生まれています。
有名どころだと、DCGAN(Deep Convolutional GAN)は畳み込み層を使って画像生成の品質を上げたものですし、WGAN(Wasserstein GAN)は訓練の安定性を改善したバージョンです。最近だとStyleGANとか、めちゃくちゃ高品質な顔画像を生成できるようになってます。
Conditional GANでは、「こういう特徴の画像を生成して」みたいに条件を指定できるようになったし、CycleGANでは画像のスタイル変換(馬をシマウマに変えるとか)ができるようになりました。応用範囲が本当に広いですね。
実際の応用例
GANsは今、いろんなところで使われています。画像生成はもちろんですが、低解像度の画像を高解像度にする超解像、白黒写真をカラーにする着色、医療画像での異常検知、さらには創薬での新しい分子構造の生成なんかにも使われてます。
データ拡張にも便利で、訓練データが少ないときに、GANsで人工的にデータを増やすみたいな使い方もできます。ただ、deepfakeみたいに悪用されるリスクもあるので、倫理的な側面も考えないといけないですね。
まとめ
GANsは、「競争によって成長する」というシンプルなアイデアで、画像生成の世界を変えました。2014年の論文発表から10年以上経ちますが、今でもその影響は色濃く残っています。
最近ではStable DiffusionとかMidjourneyとか、さらに進化した技術が出てきてますけど、GANsで培われたアイデアは今でも重要です。画像生成AIに興味がある人なら、一度は理解しておいて損はない技術だと思います。
訓練の不安定性とか、実装の難しさとか、課題もまだまだありますが、それも含めてGANsは面白い研究テーマです。興味を持った方は、ぜひ自分でも実装してみてください。きっと新しい発見があるはずです。
参考文献
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Networks. Advances in Neural Information Processing Systems, 27.
- 論文: https://arxiv.org/abs/1406.2661
- 実装コード: https://github.com/goodfeli/adversarial

コメント